Archivos Mensuales: julio 2018
¿Cómo escoger el tamaño de mi Máquina Virtual de Azure? – Serie VII – Maquinas de alto rendimiento.
![]() Buenos dias,
Buenos dias,
Por fin terminamos esta serie de posts sobre ¿Cómo escoger el tamaño de mi Máquina Virtual de Azure? Bieeennn!!!! Hoy hablaremos de las VMs Máquinas de alto rendimiento, concretamente de la Serie H y las VMs de gama alta de la Serie A,
¿Que nos proporcionan este tipo de VMs?
Las máquinas virtuales de las que vamos hablar hoy se han diseñado especialmente para satisfacer necesidades de alto nivel y son para cubrir necesidades de alto rendimiento, sin olvidarnos de alta disponibilidad, equilibrio de carga y escalabilidad.
Algunos casos de uso son, por ejemplo, informática de alto rendimiento, procesamiento por lotes, el análisis o el modelado molecular y dinámica de fluidos, HPC Clusters, , vamos lo de todos los dias, conjuntos de supercomputadoras unidas mediante redes de alta velocidad que se comportan como si fuesen un único recurso computacional.

Consideraciones a tener en cuenta:
Ya lo hemos comentado en otros posts pero, recalcamos algunas consideraciones a tener en cuenta sobre este tipo de VMs:
- Estas VMs no están disponibles para todas las regiones. Podemos consultar la disponibilidad via este enlace: Productos disponibles por región.
- Es posible que para utilizar este tipo de VMs necesitemos aumentar la cuota de núcleos (por región) de la suscripción de Azure. Para solicitar un aumento de dicha cuota hay que abrir una solicitud de soporte técnico al cliente en línea .
- Debido a su hardware especializado, solo se puede cambiar el tamaño de las instancias de proceso intensivo dentro de la misma familia de tamaño (serie H o serie A de proceso intensivo). Por ejemplo, una máquina virtual de la serie H solo se puede cambiar de un tamaño de serie H a otro. Además, no se admite el cambio de tamaño de un tamaño que no sea de proceso intensivo a un tamaño que sí lo sea.
- Hay que instalar la solución gratuita de HPC de Microsoft para crear un clúster de proceso en Azure: Microsoft HPC Pack,
- Los sistemas operativos soportados son Windeows Server 2012 en adelante.

Serie H
Como hemos comentado al inicio del post, el hardware que ejecuta estos tamaños está diseñado y optimizado para aplicaciones de proceso intensivo que consumen muchos recursos de red, incluidas las aplicaciones de clúster de proceso de alto rendimiento (HPC), para modelado y simulaciones.
Estas máquinas virtuales se basan en la tecnología del procesador Intel Haswell, en concreto, los procesadores E5-2667 V3 con tamaños de 8 y 16 núcleos que ofrecen memoria DDR4 y almacenamiento basado en SSD local. La serie H ofrece una importante capacidad de CPU, una red Infiniband opcional para RDMA y baja latencia, ademas de varias configuraciones de memoria RAM para atender requisitos de proceso intensivo.
Estos son las distintas opciones que tenemos a nuestra disposición:

Serie A
Como detalles a tener en cuenta, la serie A8-A11 utiliza Intel Xeon E5-2670 a 2,6 GHz. Estas son las características básicas de las A8-A11 en comparación con las de la serie H:

Si buscamos diferencias entre ellas…:
- Las VMs de la serie H son mas nuevas que las A8-A11, La serie H es de finales del 2016 y la serie A8-A9 son de 2015 y las A10-A11 son de finales del 2015.
- El tope de GB de memoria RAM.
- la posibilidad de acceso a discos SSD Local
- Precio. buscar, comparar y …..
Se acabó el mes de julio, ahora toca descansar y decidir qué hacemos la temporada que viene. Tiene que ser algo distinto, en caso contrario solo queda retirarnos del mundo del Blogging.
Buenas vacaciones a todos,
¿Cómo escoger el tamaño de mi Máquina Virtual de Azure? – Serie VI – Maquinas optimizadas para GPU.
![]() Buenos dias,
Buenos dias,
Penúltimo post de esta serie. Hoy vamos a comentar aquellas VMs que están optimizadas para el uso de GPU, concretamente hablaremos de la Serie N.
¿Que nos proporcionan este tipo de VMs?
Los tamaños de máquina virtual optimizada para GPU son máquinas virtuales especializadas con GPU de NVIDIA.
Estos tamaños están diseñados para cargas de trabajo de proceso intensivo, uso intensivo de gráficos y visualización y ayudan a los clientes a impulsar la innovación con características como visualización remota de alto nivel, aprendizaje exhaustivo y análisis predictivo.
Entrando algo mas en detalle:
- Los tamaños NC, NCv2, NCv3 y ND están optimizados para las aplicaciones de uso intensivo de procesos y red, así como algoritmos, incluidas aplicaciones basadas en CUDA y OpenCL y simulaciones de inteligencia artificial y aprendizaje profundo.
- NV, los tamaños están optimizados y diseñados para la visualización remota, streaming, juegos, codificación y escenarios VDI mediante marcos como OpenGL y DirectX.
Está claro el uso de esta familia de VMs de Azure 😉
Consideraciones a tener en cuenta:
- Estas VMs no están disponibles para todas las regiones. Podemos consultar la disponibilidad via este enlace: Productos disponibles por región.
- Este tipo de IaaS solo se puede implementar en el modelo de implementación de Resource Manager, olvidaros quien seguis implementado en modo Classic.
- Discos que soportan los diferentes modelos: HDD vs SSD
- Las máquinas virtuales NC y NV solo admiten discos de máquina virtual respaldados por Disk Storage (HDD) estándar.
- Las máquinas virtuales NCv2, ND y NCv3 solo admiten discos de máquina virtual respaldados por Disk Storage (SSD) Premium.
- Es posible que para utilizar este tipo de VMs necesitemos aumentar la cuota de núcleos (por región) de la suscripción de Azure y la cuota independiente para núcleos NC, NCv2, NCv3, ND o NV. Para solicitar un aumento de dicha cuota hay que abrir una solicitud de soporte técnico al cliente en línea .
- Hay que instalar/actualizar drivers de NVIDIA en las VMS. Os dejo este enlace que explica los pasos a realizar.
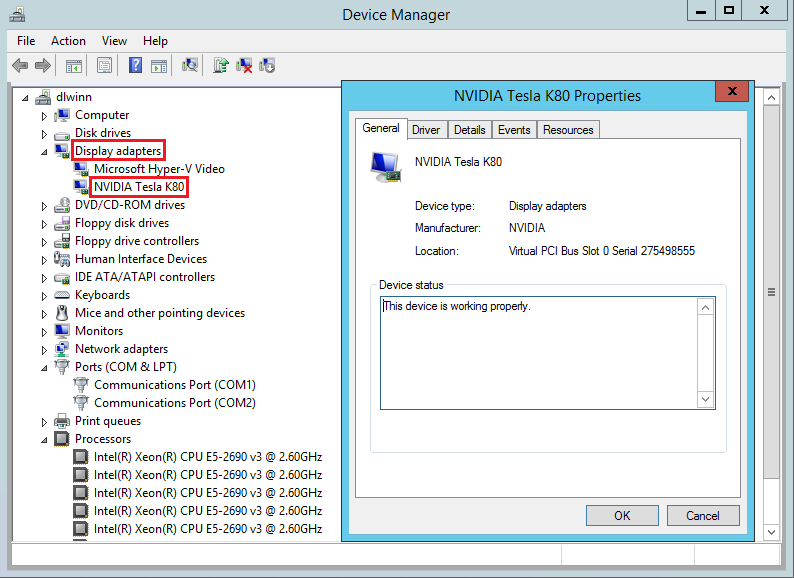
Nos centramos ahora en los tres submodelos de instancias de esta familia, obviamente orientadas a distintas cargas de trabajo:
Serie NC
Se centra en cargas de trabajo de alto rendimiento. Como se puede observar hay versión 1, 2 y 3, sobre todo por cambio de tecnología y chip de NVIDIA:
- Las VM de la serie NC disponen de una tarjeta Tesla K80 de NVIDIA. Los usuarios pueden trabajar con datos con mayor rapidez aprovechando CUDA para las aplicaciones de exploración de energía, simulaciones de accidentes, representación de trazado de rayos, aprendizaje profundo y mucho más. La configuración NC24r proporciona una interfaz de red de baja latencia y alto rendimiento optimizada para cargas de trabajo de computación paralelas estrechamente unidas.
- Las VM de la serie NCv2 disponen de tecnología de GPU NVIDIA Tesla P100. Estas GPU pueden duplicar el rendimiento del trabajo de computación de la serie NC. Los clientes pueden aprovechar estas GPU actualizadas para cargas de trabajo de HPC tradicionales, como la creación de modelos de embalses, secuenciación de ADN, el análisis de proteínas, lrealización de simulaciones Monte Carlo y otras. La configuración NC24rs v2 proporciona una interfaz de red de baja latencia y alto rendimiento optimizada para cargas de trabajo de computación paralelas estrechamente unidas.
- Las VM de la serie NCv3 disponen de tecnología de GPU NVIDIA Tesla V100. Estas GPU pueden aumentar 1,5 veces el rendimiento del trabajo de computación de la serie NCv2. Los clientes pueden aprovechar estas GPU actualizadas para cargas de trabajo de HPC tradicionales, como la creación de modelos de embalses, la secuenciación de ADN, el análisis de proteínas, la realización de simulaciones Monte Carlo y otras. La configuración NC24rs v3 proporciona una interfaz de red de baja latencia y alto rendimiento optimizada para cargas de trabajo de computación paralelas estrechamente unidas.

Serie ND
Estas VMs son una novedad incorporada a la familia GPU diseñada para cargas de trabajo inteligencia artificial y aprendizaje profundo. Ofrecen un rendimiento excelente para el aprendizaje y la inferencia. Las instancias de ND disponen de tecnología de GPU Tesla P40 de NVIDIA.
Estas instancias brindan un rendimiento excelente para operaciones de punto flotante de precisión única, para cargas de trabajo de inteligencia artificial que usan Microsoft Cognitive Toolkit, TensorFlow, Caffe y otros marcos. La serie ND también ofrece una memoria de la GPU de un tamaño muy superior (24 GB), lo que permite adaptarse a modelos de redes neurales mucho más grandes. Al igual que la serie NC, la serie ND presenta una configuración con una baja latencia secundaria, una red de alta productividad mediante RDMA y conectividad InfiniBand para que pueda ejecutar trabajos de aprendizaje a gran escala que abarquen muchas GPU.
Serie NV
Y no es la carretera de Extremadura, esta última serie, de momento, dispone de tarjetas GPU Tesla M60 de NVIDIA y tecnología NVIDIA GRID para aplicaciones aceleradas de escritorio y escritorios virtuales donde los clientes pueden visualizar sus datos o simulaciones. Los usuarios pueden visualizar sus flujos de trabajo con muchos gráficos en las instancias de NV para obtener una excelente funcionalidad gráfica y ejecutar, además, cargas de trabajo de precisión únicas, como la codificación y la representación.Cada GPU de instancias de NV viene con una licencia de GRID. Esta licencia le ofrece flexibilidad para utilizar una instancia de NV como estación de trabajo virtual para un solo usuario; también se pueden conectar 25 usuarios simultáneos a la VM para un escenario de aplicación virtual.
| Tamaño | vCPU | Memoria: GiB | GiB de almacenamiento temporal (SSD) | GPU | Discos de datos máx. | Nº máx. NIC | Estaciones de trabajo virtuales | Aplicaciones virtuales |
|---|---|---|---|---|---|---|---|---|
| Standard_NV6 | 6 | 56 | 340 | 1 | 24 | 1 | 1 | 25 |
| Standard_NV12 | 12 | 112 | 680 | 2 | 48 | 2 | 2 | 50 |
| Standard_NV24 | 24 | 224 | 1440 | 4 | 64 | 4 | 4 | 100 |
Tanto la serie NC como la serie ND presentan interconexión opcional de InfinBand para los tamaños más grandes a fin de permitir rendimiento que escale verticalmente.
Buen fin de semana,
Roberto
Como crear tu rol RBAC personalizado para Azure.
 Buenos dias,
Buenos dias,
Hace poco en una visita a un buen cliente me comentó que determinados usuarios eran capaces de gestionar las máquinas virtuales que tenia en producción, reiniciarlas, cambiarlas el tamaño, etc., asi como trastear con las bases de datos de Azure SQL, y realmente nos dimos cuenta que un usuario con un rol administrativo, que solo se tenia que encargar de gestionar los servicios IaaS y PaaS, podria darse la casualidad de que accediese al contenido de una base de datos.
En ese momento nos surgió la duda sobre qué permisos tenia asignados ese usuario en concreto y cuales eran los permisos que realmente tenia que tener, una situación algo mas habitual de lo que pensamos.

Azure Active Directory, desde que estamos en ARM (v2 de Azure), disponemos de toda la potencia del Control de Acceso basado en Roles, vamos lo que conocemos por RBAC y, en el caso de no encontrar un Rol creado por defecto con las caracterísitcas que necesitamos pues …….. lo creamos y personalizamos……. sin olvidarnos de las premisas ya aprendias de los principios básicos de «minimos privilegios»
¿Que tareas y accesos necesitamos que tenga nuestro usuario administrador de PaaS e IaaS?
- Poder apagar, reiniciar, VMs,
- Realizar un Resizing de IaaS.
- Gestionar las copias de seguridad de las mismas.
- Gestionar los Servidores de Azure SQL.
- Gestión de las bases de datos de Azure SQL
- No tener acceso al contenido de las bases de datos de Azure SQL.
- …..
Estos roles se pueden asociar tanto a usuarios como a grupos, recordar, siempre mejor asignar roles a grupos y posteriormante incluir al usuario dentro del grupo, Best Practices. Ademas, podemos aplicar estos privilegios de acceso tanto a nivel de la suscripción como a nivel de Grupos de Recursos, lo que se conoce como ámbito de aplicación. Un detalle a tener en cuenta es que la aplicación de estos privilegios conlleva a la suma de los mismos, en el caso de que haya múltiples pertenencias a grupos.

Hay que decir que tenemos muchos roles RBAC predefinidos que, probablemente, cumplan con nuestras necesidades, para muestra un boton ….

# Listar roles RBACGet-AzureRmRoleDefinition | Format-Table Name, Description
Get-AzureRmRoleDefinition «Virtual Machine Contributor»Get-AzureRmRoleDefinition «SQL Server Contributor»

Creación del rol personalizado.
{«Name»: «Jordi custom Role»,«Id»: null,«IsCustom»: true,«Description»: «Lets you manage virtual machines, but not access to them, and not the virtual network or storage account they’re connected to, and Lets you manage SQL servers and databases, but not access to them, and not their security -related policies.»,«Actions»: [«Microsoft.Authorization/*/read»,«Microsoft.Compute/availabilitySets/*»,«Microsoft.Compute/locations/*»,«Microsoft.Compute/virtualMachines/*»,«Microsoft.Compute/virtualMachineScaleSets/*»,«Microsoft.DevTestLab/schedules/*»,«Microsoft.Insights/alertRules/*»,«Microsoft.Network/applicationGateways/backendAddressPools/join/action»,«Microsoft.Network/loadBalancers/backendAddressPools/join/action»,«Microsoft.Network/loadBalancers/inboundNatPools/join/action»,«Microsoft.Network/loadBalancers/inboundNatRules/join/action»,«Microsoft.Network/loadBalancers/probes/join/action»,«Microsoft.Network/loadBalancers/read»,«Microsoft.Network/locations/*»,«Microsoft.Network/networkInterfaces/*»,«Microsoft.Network/networkSecurityGroups/join/action»,«Microsoft.Network/networkSecurityGroups/read»,«Microsoft.Network/publicIPAddresses/join/action»,«Microsoft.Network/publicIPAddresses/read»,«Microsoft.Network/virtualNetworks/read»,«Microsoft.Network/virtualNetworks/subnets/join/action»,«Microsoft.RecoveryServices/locations/*»,«Microsoft.RecoveryServices/Vaults/backupFabrics/protectionContainers/protectedItems/*/read»,«Microsoft.RecoveryServices/Vaults/backupFabrics/protectionContainers/protectedItems/read»,«Microsoft.RecoveryServices/Vaults/backupFabrics/protectionContainers/protectedItems/write»,«Microsoft.RecoveryServices/Vaults/backupFabrics/backupProtectionIntent/write»,«Microsoft.RecoveryServices/Vaults/backupPolicies/read»,«Microsoft.RecoveryServices/Vaults/backupPolicies/write»,«Microsoft.RecoveryServices/Vaults/read»,«Microsoft.RecoveryServices/Vaults/usages/read»,«Microsoft.RecoveryServices/Vaults/write»,«Microsoft.ResourceHealth/availabilityStatuses/read»,«Microsoft.Resources/deployments/*»,«Microsoft.Resources/subscriptions/resourceGroups/read»,«Microsoft.Sql/locations/*/read»,«Microsoft.Sql/servers/*»,«Microsoft.Storage/storageAccounts/listKeys/action»,«Microsoft.Storage/storageAccounts/read»,«Microsoft.Support/*»],«NotActions»: [«Microsoft.Sql/servers/auditingPolicies/*»,«Microsoft.Sql/servers/auditingSettings/*»,«Microsoft.Sql/servers/databases/auditingPolicies/*»,«Microsoft.Sql/servers/databases/auditingSettings/*»,«Microsoft.Sql/servers/databases/auditRecords/read»,«Microsoft.Sql/servers/databases/connectionPolicies/*»,«Microsoft.Sql/servers/databases/dataMaskingPolicies/*»,«Microsoft.Sql/servers/databases/extendedAuditingSettings/*»,«Microsoft.Sql/servers/databases/schemas/tables/columns/sensitivityLabels/*»,«Microsoft.Sql/servers/databases/securityAlertPolicies/*»,«Microsoft.Sql/servers/databases/securityMetrics/*»,«Microsoft.Sql/servers/databases/sensitivityLabels/*»,«Microsoft.Sql/servers/databases/vulnerabilityAssessments/*»,«Microsoft.Sql/servers/databases/vulnerabilityAssessmentScans/*»,«Microsoft.Sql/servers/databases/vulnerabilityAssessmentSettings/*»,«Microsoft.Sql/servers/extendedAuditingSettings/*»,«Microsoft.Sql/servers/securityAlertPolicies/*»],«DataActions»: [],«NotDataActions»: [],«AssignableScopes»: [«/subscriptions/XXXX-xxxx-XXXXX-xxxxx/resourceGroups/Desktops«]
Aplicación del Rol personalizado.
Comprobación de la creación del rol personalizado


Perfecto!!!!! Esto es lo que queriamos!!!!!
Aqui os dejo un video muy interesantes, del gran Paco Sepulveda (@FMSepulveda), tomar nota y apuntaros su Twitter y su gran blog:
Un abrazo,
Roberto
¿Cómo escoger el tamaño de mi Máquina Virtual de Azure? – Serie V – Maquinas con Almacenamiento optimizado.
![]() Buenos dias,
Buenos dias,
Aqui seguimos, en Julio, esperando las vacaciones, …., que no llegan, jajaja.
Hoy os voy a comentar aquellas VMs que están optimizadas para el almacenamiento, concretamente hablaremos de la Serie L,
¿Que nos proporcionan este tipo de VMs?
Concretamente, esta familia de máquinas son ideales para aplicaciones que requieren baja latencia, alto rendimiento y almacenamiento de disco local de gran tamaño.
Estas VMs utilizan los procesadores E5 Xeon v3 con tamaños de máquina virtual de 4, 8, 16 y 32 núcleos que se basan en la tecnología del procesador Intel Haswell. Ademas, esta serie, al igual que otras que ya hemos visto, admite disco SSD local de hasta 6 TB y ofrece un gran rendimiento de E/S de almacenamiento. Se empezaron a utilizar en Marzo del año pasado, 2017.
Algunos casos de uso son, por ejemplo, bases de datos SQL, bases de datos NoSQL, como Cassandra, MongoDB, Cloudera o Redis.
Aqui os dejo una tabla con las métricas de rendimiento de los discos
| Tamaño | vCPU | Memoria: GiB | GiB de almacenamiento temporal (SSD) | Discos de datos máx. | Rendimiento máximo de almacenamiento temporal: IOPS/MBps | Rendimiento de disco no en caché máx.: E/S por segundo / Mbps |
| Standard_L4s | 4 | 32 | 678 | 16 | 20 | 5000 / 125 |
| Standard_L8s | 8 | 64 | 1,388 | 32 | 40 | 10 000 / 250 |
| Standard_L16s | 16 | 128 | 2,807 | 64 | 80 000 / 800 | 20 000 / 500 |
| Standard_L32s 1 | 32 | 256 | 5,63 | 64 | 160 | 40 000 / 1000 |
Detalles a tener en cuenta sobre estas medidas son:
- La capacidad de almacenamiento se muestra en unidades de GiB o 1024^3 bytes. Cuando compare discos que se miden en GB (1000^3 bytes) con discos que se miden en GiB (1024^3), hay que tener en cuenta que los números que representan la capacidad en GiB pueden parecer más pequeños. Por ejemplo, 1023 GiB = 1098.4 GB
- La medición del rendimiento de disco se ha realizado en operaciones de entrada/salida por segundo (E/S por segundo) y Mbps, donde Mbps = 10^6 bytes/s.
- Detalle a tener muy en cuenta, los discos de datos de la serie Ls no pueden funcionar en modo caché, el modo de caché del host debe estar establecido en Ninguno.
Si accedo a mi subscripción de Azure y trato de desplegar una IaaS de esta familia me ocurre lo siguiente:

Como podeis observar solo tengo disponibles las hermanas pequeñas de la familia, las medianas tengo cuota insuficiente, asi como las v2, tamaños no disponibles en mi zona, West Europe. 😉 .
Buena semana a todos,
Roberto
