Archivo de la categoría: Rendimiento
System Center Advisor. Monitorización de nuestros servidores desde la nube.
Buenas tardes,
Hoy os comento esta otra herramienta que Microsoft pone a nuestra disposición de una manera gratuita, System Center Advisor (SCA) para utilizarla como herramienta de análisis del estado de salud de nuestra infraestructura de servidores Microsoft Windows.
Realmente es como un mini SCOM, producto de la familia System Center destinado, principalmente, a la Monitorización y generación de alertas, aunque hay que decir que solo nos guarda los datos recolectados de los últimos 5 dias, recordar que es Free.
¿Que nos proporciona esta herramienta que no tengamos ya?
- Comprobación del estado de salud.
- Cumplimiento de las mejores prácticas en equipos tales como:
- Windows Server 2012
- Windows Server 2008 (Datacenter, Enterprise y Standard).
- Windows Server 2008 R2 (Datacenter, Datacenter, Enterprise y Standard con o sin Hyper-V).
- Hyper-V Server 2012
- Hyper-V Server 2008 R2
- SQL Server 2008 y posteriores.
- Microsoft Sharepoint Server 2010
- Microsoft Exchange Server 2010
- Microsoft Lync Server 2010 y 2013.
- System Center 2012 SP1 – Virtual Machine Manager
- Compatibilidad 100% con Azure.
Tendremos que instalar un agente monitor y otro agente gateway en nuestra infraestructura de servidores para que reporten directamente a la plataforma Azure.
Comentar que existen dos versiones de este producto, la gratuita, que es la que os voy a comentar y la que reporta directamente a SCOM. Aqui os dejo las principales diferencias entre ambas versiones:

ALTA EN EL SERVICIO.
Primero tendremos que darnos de alta en el servicio con una cuenta Microsoft Account, ya sabeis @outlook.com, live.com, Office365, etc. En el caso de no tenerla nos pedirá un nombre de cuenta, nuestro nombre y dirección de correo. Una vez aceptadas las condiciones empezaremos a realizar el despliegue.

DESPLIEGUE.
SCA nos ayudará desde el principio con un asistente que nos irá guiando sobre qué tenemos que descargar e instalar en cada momento. En la primera imagen nos muestra un gráfico de cómo será el despliegue de la herramienta:
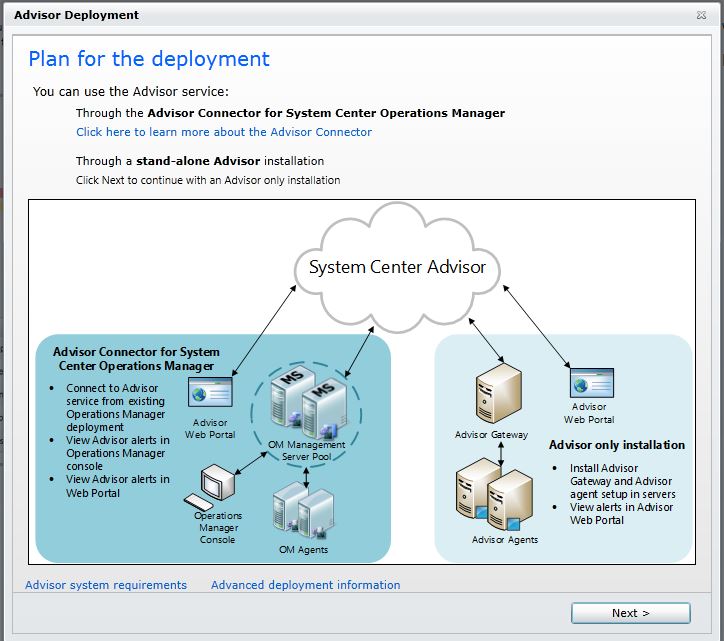
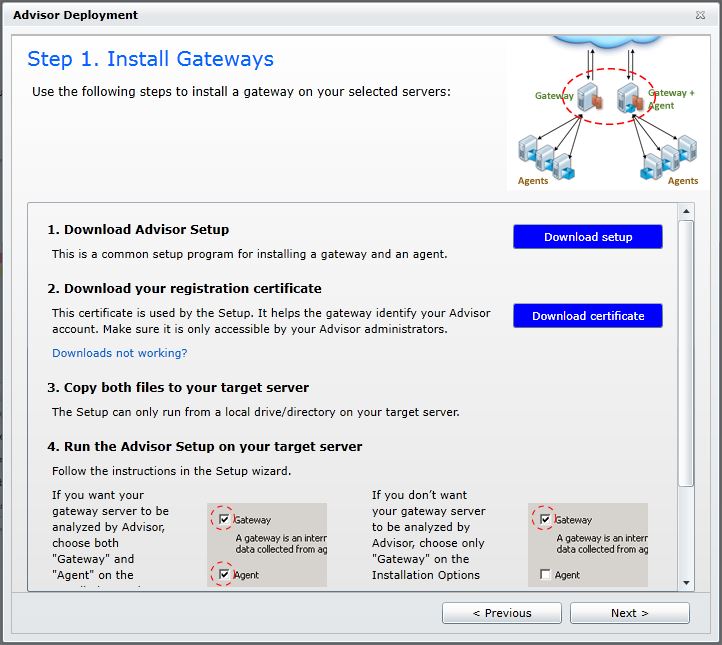
El primer paso será la instalación del agente que hará de Gateway o pasarella entre nuestra infraestructura de servidores y Azure. Procederemos a descargarnos tanto el software como el certificado que utilizaremos para cifrar las comunicaciones:
El segundo paso es la instalación del agente, propiamente dicho, de SCA, que, como ya nos daremos cuenta, es el mismo agente/servicio que se utiliza en SCOM:

INSTALACION DE AGENTES.
Los requisitos necesarios para la instalación de ambos agentes son .Net Framework 3.5, así que la mayoría de nuestros servidores lo cumpliran. Lanzamos el ejecutable y nos aparece la ventana de bienvenida:
 Aceptaremos los términos de la licencia:
Aceptaremos los términos de la licencia:
 Definiremos una ruta donde instalar el producto o dejaremos la ruta por defecto:
Definiremos una ruta donde instalar el producto o dejaremos la ruta por defecto:
Llegados a este punto, dependiendo del rol que vaya a tener cada servidor instalaremos el agente «Gateway» y el Agente de SCA.

Recordar que este servidor tiene que tener acceso a Internet, aunque supongo que eso ya lo tenías claro.
 Siguiente, ….
Siguiente, ….
 Listos para empezar a instalar:
Listos para empezar a instalar:

Instalando, que es gerundio …

Finaliza la instalación del producto:

CONFIGURACION INICIAL
En los siguientes pasos, tendremos que instalar el certificado para cifrar las comunicaciones y verificar que la comunicación entre el Portal en Azure de SCA y nuestro Gateway es correcto, así como entre nuestro Gateway y nuestros Servidores.
Agente Gateway y Agente SCA
Desde nuestro servidor Gateway, se lanzará un asistente donde, inicialmente, definiremos cómo accedemos a Internet así como cargaremos el certificado:

Nos informará si queremos instalar las últimas actualizaciones a nuestro servidor , por defecto nos pone que si:
Nos confirmará los pasos a seguir:
Nos va mostrando todos y cada uno de los chequeos que realiza y …. todo correcto, hay conexión con Azure:
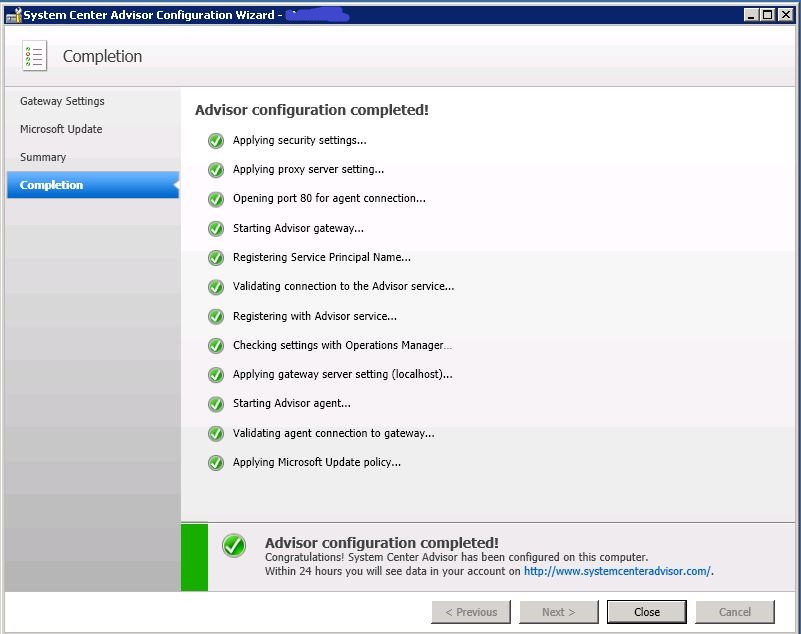
Como hemos dicho que si haga un Windows Update … pues se pone a ello

Y ya nos aparecen datos en nuestra consola, aunque solo son de la conexión pero podemos ver ya ambos agentes conectados. Recordar que habrá que esperar 24 horas para que empiece el reporte de toda la información:

Agente SCA
Similar a los pasos anteriores solo que solo tenemos que especificar el servidor con el rol de Gateway:

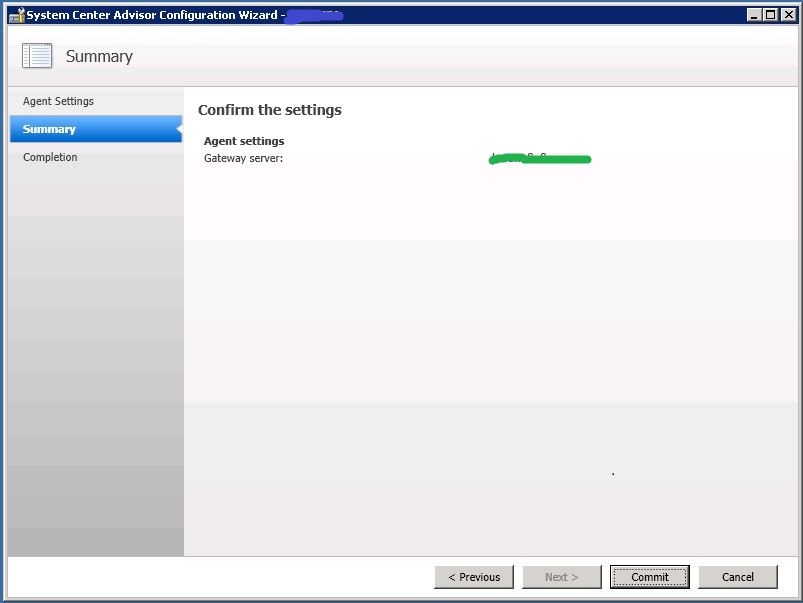
Nos aparecerá el Sumario:
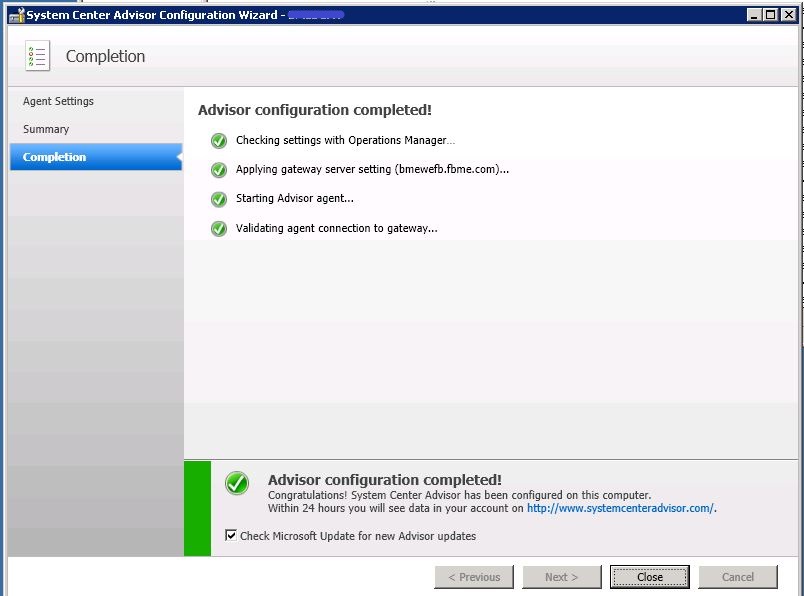
Y, nuevamente, nos va mostrando todos y cada uno de los chequeos que realiza y …. todo correcto, hay conexión con Azure:
Nos irán apareciendo todos los servidores en nuestra consola:
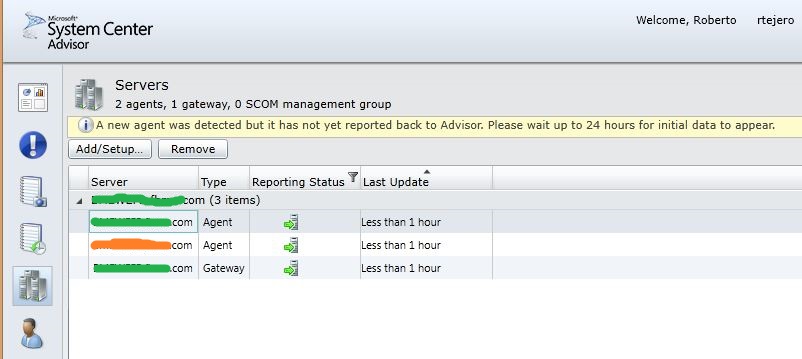
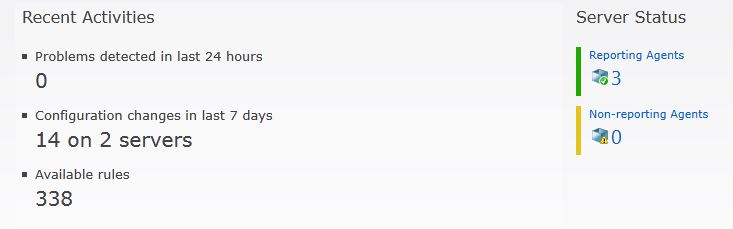
Ahora, podremos analizar el estado de nuestras configuraciones, cuándo ha habido cambios, sobre todo, como dice Kilian Arjona, para detectar si despues de un cambio tenemos un problemas, ver el estado de la replicación de nuestros Controladores de Dominio, etc., etc. Fijaros, 14 cambios en 2 servidores en los últimos 7 dias…..
DETALLES DE LA CONFIGURACION
Por un lado si nos fijamos en los servicios generados en los servidores al instalar los agentes, vemos que son los de SCOM:

Y, por otro, las rutas donde se ubican los logs son las siguientes:
- Logs del Gateway.- C:Program FilesSystem Center AdvisorGatewayDataLogs
- Logs del Cliente.- C:Program FilesSystem Center AdvisorAgentDataLogs
Lecturas recomendadas
Os dejo estos dos post muy buenos de dos maquinas, Kilian Arjona de Ncora y eManu, espectacular en la exposición. Poco o muy poco he podido aportar a lo dicho por ambos, solo la experiencia de instalarlo y echarle un vistazo.
– Blog de eManu. (@emanu).
Ya queda muy, pero que muy poco para las vacaciones.
Hyper-V Performance – Parte V – NUMA.
Para finalizar esta serie de Post hoy nos metemos con NUMA. Hago una breve introducción sobre esta serie de posts sobre Hyper-V Performance. Hemos hablado de los siguientes puntos:
- CPU.
- Memoria.
- Almacenamiento.
- Red.
Creo que primero trataremos de explicar qué es NUMA y para qué sirve. Si buscamos la definición canónica de NUMA, desde la Wikipedia nos dice que es «El acceso a memoria no uniforme». Yo me quedé como estaba y seguí buscando por internet.
 Al final me quedo con esta difinición. «Sistema que realiza una asociación de memoria de uso a CPU con la finalidad de evitar cuellos de botella». Aqui os dejo un enorme post sobre Numa e Hyper-V, del gran Daniel Matey. Es de hace un par de años pero poco han cambiado las cosas.
Al final me quedo con esta difinición. «Sistema que realiza una asociación de memoria de uso a CPU con la finalidad de evitar cuellos de botella». Aqui os dejo un enorme post sobre Numa e Hyper-V, del gran Daniel Matey. Es de hace un par de años pero poco han cambiado las cosas.
Un detalle que me llamó la atención es como realiza la asociación CPU vs Memoria cada constructor. Como ejemplo:
- Intel.- Asocia cada 4 Cores = 1 Nodo NUMA.
- AMD.- Asocia cada 6 Cores = 1 Nodo NUMA.
Hyper-V, automáticamente utilizará la mejor opción posible y configurará la máquina virtual (VM) para optimizar la topologia existente NUMA. Los problemas aparecen cuando utilizamos memoria dinámica y cuando las VMs requieren mas memoria que la asignada a cada nodo NUMA.
Ahora, a lo nuestro, verificar y medir el rendimiento:
- \\Hyper-V Hypervisor Virtual Processor(*)\% Remote RunTime.- El menor valor representará un buen rendimiento. Cuanto mas cercano a 0 mucho mejor.
- \\Hyper-V VM VID Partition(*)\% Remote Physical Pages.- Lo ideal es que esté lo mas cercano posible a 0. Esto quiere decir que la VM estará utilizando únicamente recursos locales, de su nodo NUMA.

Otras recomendaciones que realiza Microsoft:
- Los Componentes de integración (ICS) tienen que ser los recomendados/sugeridos dependiendo de la versión de Hyper-V donde esté alojada la VM.
- Hyper-V debería ser el único rol habilitado en el Host.
- Evitar tener una mezca del VMs con sus ICS y VM sin sus ICS, penalizará el rendimiento del Host.
- No asignar mas de 2 procesadores a aquellas VM con sistema operativo 2003. (Esta me ha gustado mucho).
- Por favor, no usuar «legacy network adapters» aumenta considerablemente el «Context Switching». Lo explicamos en el Post sobre red.
Ya queda menos.
Bibliografía.
Hyper-V Performance – Parte IV – Red.
 Me quedé sin espacio en la base de datos de mi WordPress en Azure, así que continuamos en «MasRobeznoQueNunca» hasta que solucione este pequeño problema.
Me quedé sin espacio en la base de datos de mi WordPress en Azure, así que continuamos en «MasRobeznoQueNunca» hasta que solucione este pequeño problema.
Hoy continuamos con la monitorización de la red.
Después de haber visto la monitorización mas complicada como es la de Almacenamiento o la de memoria, la monitorización de rede la vamos a basar en dos simples contadores, uno para la tarjeta del host y otro para la tarjeta de las Máquinas Virtuales (VM):
a) Tarjeta de red del Host.- El siguiente contador indica el total de Bytes por segundo tanto de tráfico de entrada como de salida en una tarjeta de red física (NIC).
Network InterfaceBytes Total/Sec
Con la siguiente horquilla de valores recomendados:

No tenemos que olvidar detalles tan importantes como la velocidad de nuestra tarjeta de red, como por ejemplo:
- NIC de 10 GB puede enviar cerca de 1250 millones de bytes/sec
- NIC de 1 GB puede enviar cerca de 125 millones de bytes/sec
- NIC de 100 MB puede enviar cerca de 12,5 millones de bytes/sec
y la velocidad de los Switches o Routers a los que está conectado, ya que aunque tengamos la posibilidad de configurar las tarjetas de red a 10 GB si los Switches son de 1GB ……
.
b) Tarjeta de red de la VM.- En el caso de que queramos estudiar el tráfico de las tarjetas de red virtuales (vNIC), utilizaremos el siguiente contador que representa el número total de byts que atraviesan dicho adaptador virtual.
Hyper-V Virtual Network AdapterBytes Total/Sec
Utilizaremos la misma horquilla descrita en el punto anterior.
Buena semana a todos.
Hyper-V Performance – Parte III – Almacenamiento.
.jpg)
Continuamos con esta serie de Post sobre como medir el rendimiento de nuestros Hyper-V, despues de la CPU y la memoria RAM, hoy nos toca el almacenamiento.
El almacenamiento suele ser uno de los puntos donde se originan mas cuellos de botella en nuestra infraestructura. Detectar dichos problemas suele ser uno de los dolores de cabeza mas frecuentes del informático. En Hyper-v no va a dejar de ocurrir lo mismo. Lo vamos a dividir en tres partes:
a) Logical Disk.– Tenemos estos tres contadores de rendimiento recomendados de Disco lógico, como podreis intuir se trata de monitorizar si tenemos latencia en lectura, escritura y en transferencia por segundo, en valores medios:
LogicalDiskAvg Disk sec/Read
LogicalDiskAvg Disk sec/Write
LogicalDisk(*)Disk Transfers/sec (IOPS desde el punto de vista de Windows).
Utilizaremos el siguiente baremo recomendado por Microsoft para saber si nuestros discos están en estado saludable o tenemos latencia:
b) Physical Disk.– Tenemos los mismos contadores de rendimiento recomendados que en punto de Disco lógico, lectura, escritura y transferencia por segundo en valores medios. Además utilizaremos la misma horquilla para saber si tenemos latencia o no.
Physical DiskAvg Disk sec/Read
Physical DiskAvg Disk sec/Write
LogicalDisk(*)Disk Transfers/sec
En el caso que estemos utilizando Cluster Shared Volumes (CSV) conectados como discos Passthrough, tendremos que monitorizarlos no solo para saber si tenemos latencia, también para ver el grado de fragmentación de dicho disco.
Physical Disk(*)Disk Transfers/sec (* CSV monitoring)

También tendremos que tener especial cuidado si hemos montado nuestra infraestructura de virtualización aprovechando las bondades de Server Message Block (SMB), ya en versión 3, con los siguientes contadores:
SMB Clients ShareAvg Disk sec/Read
SMB Clients ShareAvg Disk sec/Write
Es dificil poner un baremo en estos contadores ya que siempre dependerá de la infraestructura de red que tengamos.
c) Hyper-V Storage.- Estos contadores representan el número total de bytes que han sido leidos o escritos por segundo en el dispositivo virtual. Es complicado poner un baremo ya que en todo momento depende del tipo de almacenamiento físico que estemos utilizando:
Hyper-V Virtual Storage DeviceRead bytes/Sec
Hyper-V Virtual Storage DeviceWrite bytes/Sec
Cada fichero VHD o VHDX tendrá su propia instancia de contador de rendimiento y lo utilizaremos para determinar qué disco tiene mas o menos utilización (IOPS).
Como podreis comprobar hay innumerables post en blogs sobre el rendimiento y el almacenamiento, hay mucha información, en general, sobre el rendimiento. Os enumero unos poquitos:
Hyper-V Performance – Parte II – Consumo de Memoria.

Continuo con esta serie de Post sobre como medir el rendimiento de nuestros Hyper-V, despues de la CPU hoy llega la memoria RAM.
Obviamente lo dividimos en la parte del Host de virtualización, ya sea Windows Server 2012 con el rol de Hyper-V o sea Hyper-V server 2012, y la parte de las máquinas virtuales (VMs).
Host.- Los principales contadores para monizar la memoria del Host son los siguientes:
- MemoryAvailable MBytes.- Microsoft nos recomienda monitorizar la memoria disponible de cada Host de virtualización a través de esta orquilla de valores:

- MemoryPages /Sec.- Con este contador monitorizaremos las páginas que se están leyendo o escribiendo en disco por segundo, para tratar de detectar errores de paginación, o sea, que tengamos un caso que el sistema operativo no dispone de mas memoria disponible y está utilizando el disco duro para volcar el resto de memoria que necesita, con su correspondiente impacto negativo en el rendimiento. Microsoft nos recomienda esta orquilla de valores a la hora de medir este contador:

Como ejemplo, un alto número de paginas por segundo unido a una baja memoria disponible nos está indicando una falta de memoria en el servidor, obviamente.
Recordamos los principios básicos de la relación existente entre la memoria y la paginación a disco «a mas memoria RAM asignada a un equipo menos paginará en disco«, sin olvidarnos de que «no siempre disponemos de toda la memoria RAM que queremos y/o necesitamos».

Virtual Machines.- En este caso se nos presentan dos opciones de configuración en la gestión de la memoria:
- Sin memoria Dinámica configurada.- Al no tener configurada esta característica, utilizaríamos los mismos contadores que para un Host de virtualización. Volvemos al punto anterior.
- Con memoria Dinámica configurada.- Tenemos los siguientes contadores de rendmiento:
- Hyper-V Dinamic Memory BalancerAvailable Memory.- Este contador representa la cantidad de memoria que queda disponible en el «nodo balancer» (gestor del balanceo de memoria entre las VM cuando están configuradas con memoria dinámica), y que puede ser asignada a las VMs.
Aqui prestaremos atención a que el valor de dicho contador no esté próximo a 0, que nos indicará que el sistema está cerca del consumo del 100% de la memoria, con los consiguientes problemas de rendimiento en las mismas.
- Hyper-V Dinamic Memory BalancerPhysical Memory.- Este contador representa la cantidad de memoria en la VM. Es muy util para entender el consumo histórico de una VM.
Tendremos que tener cuidado de que el valor que nos da este contador no esté cerca de la memoria máxima asignada, ya que nos indicaría que este servidor está consumiendo toda su memoria RAM y, probablemente, esté paginando a disco y necesite mas.
- Hyper-V Dinamic Memory BalancerAverage.- Este último contador representa la presión media sobre el «nodo balancer». Esta es la orquilla de valores recomendados:

Por defecto en Windows Server 2012 con el rol de Hyper-V, automáticamente se fija una memoria para el Host. Para sistemas operativos anteriores, como Windows Server 2008 R2, necesitamos habilitar y configurar una entrada en el registro:
HKLMSOFTWAREMicrosoftWindows NTCurrentVersionVirtualization
- Nombre:MemoryReserve
- Tipo: DWORD
- Valor: Memoria a reservar en MB.
Dos cosas para terminar. Recordar que estos datos no son extrapolables al 100% a todos y cada uno de nuestros entornos, como ya dije en el Post anterior, son recomendaciones. Y, segundo, recordar, también, en el caso de configurar memoria dinámica a las VMs, qué parámetros tenemos que tener en cuenta:

Buena semana a todos,
Hyper-V Performance – Parte I – Consumo de CPU.
Aprovechando que hace poco estube en un Workshop en Microsoft sobre el rendimiento de nuestros servidores con el rol de Hyper-V, adelanto esta serie de Posts sobre «cómo medir dicho rendimiento así cómo detectar posibles cuellos de botella en nuestro entorno de virtualización».
Para empezar, me gustaría recordar este Post sobre «10 errores típicos en una revisión de salud de un entorno de Virtualización«, que considero indispensable releer cada vez que me meto en un proyecto de virtualización, independientemente del tipo de Hypervisor que se vaya a utilizar.

i) Host Processor.- Normalmente en cualquier servidor, si queremos verificar el consumo de nuestro procesador lo que haremos será cargar los siguientes contadores de rendimiento:
- Processor(*)% Processor Time
- Task Manager (ver imagen =>)
- SystemProcessor Queue Lenght
Pues en nuestro caso, para saber qué consumo tiene la partición padre, que no hay que olvidar que es una máquina virtual (VM) en si misma, ya sea Hyper-V Server 2012 o Windows Server 2012 con el rol de Hyper-V, serán los mismos.
Veamos en que rangos de consumo de tiempo de procesador nos movemos:

En el caso de que hayamos visto o intuyamos que pueda haber un problema de rendimiento en la CPU, o sea, nos hayemos en la zona de Caution o Critical, utilizaremos el contador de la Longitud de la cola del procesador, como referente inicial disponemos de la siguiente horquilla de valores que nos puede ayudar:

Siempre hay que tener en cuenta que si ocurre en un momento puntual, no pasa nada. Otra cosa es que estos valores se alcancen durante un tiempo continuado. En cuanto a la horquilla de valores, éstos son orientativos, hay que saber extrapolarlos a las situaciones reales, a la carga del servidor, a los roles que tengamos instalados en el mismo, etc., no cogerlos como una regla de tres o lo que dice el KB de Microsoft va a Misa.
ii) Logical processor.- Para medir el total del consumo de procesador por parte del Host y todas las VM, utilizaremos los siguientes contadores de rendimiento:
- Hyper-v Hypervisor Logical Processor(*)% Total Runtime
- Hyper-v Hypervisor Logical Processor(*)Context Switches /Sec
% Total Runtime, con su consiguiente horquilla de valores indicativos (si os fijais son los mismos que en el punto anterior):
Para el caso de los Content Switches, ocurren cuando el kernel cambia el procesador asignado de un subproceso a otro, verificaremos cuántos se producen por procesador y por segundo, con la consiguiente horquilla de valores indicativos:

Cuando detectamos que estamos en zona Critical, suele venir motivado por:
- Adaptadores del tipo Legacy Network.
- Mal diseño de aplicaciones.
- Drivers mal instalados.
ii) Virtual processor.- Determinar el consumo de procesador de cada VM:
- Hyper-v Hypervisor Virtual Processor(*)% Guest Runtime
Con la misma o muy parecida horquilla de valores indicativos que en el punto anterior:

Como consejo final, si detectamos que Hyper-V Hypervisor Virtual Processor (_Total)% Total Run Time (Virtual Procesor Total Run Time – VPTR) está muy alto y Hyper-V Hypervisor Logical Processor (_Total)% Total Run Time (Logical Procesor Total Run Time – LPTR) es bajo, consideremos en asignar procesadores adicionales a esa VM.
El próximo día la memoria RAM.
Exchange 2010 Architecture Report
Hola. Hoy os traigo este script que nos proporciona información arcerca de nuestra Organización de Exchange 2010. Lo podeis descargar desde Aqui.

Esta herramienta nos genera un reporte en formato HTML para presentar todos los datos recolectados donde podemos ver qué es lo que funciona y lo que no de un simple vistazo.
 Tiene tanto un acceso por Interfaz gráfica (GUI) como por comando. Esta última la podemos utilizar para generar tareas programadas y generar informes de chequeo.
Tiene tanto un acceso por Interfaz gráfica (GUI) como por comando. Esta última la podemos utilizar para generar tareas programadas y generar informes de chequeo.

Espero que os guste y os sirva.
Servicio Back Pressure en Exchange 2010.
- Normal.- Los recursos son correctos. El servidor acepta nuevas conexiones y mensajes. Todo correcto.
- Medium.- Los recursos se están acabando. Los correos desde dominios autoritativos pueden ser enviados. Dependiendo de los recursos de que se disponga, el servidor empezará a retrasar respuestas o a rechazar comandos «MAIL FROM» de otras fuentes.
- High.- Cuando se entra en este estado es que no hay recursos. Todos los flujos de mensajes se paran y se rechanzan todas las conexiones entrantes.


Para la base de datos Queue:




Medición del rendimiento – ¿Cómo detectar problemas de latencia en disco en VMware vSphere ESXi?
Continuando con las mediciones del rendimiento de nuestros servidores, llevaba tiempo para sacar un Post sobre cómo detectar problemas de latencia en discos, tanto FC, iSCSI como NFS, al menos desde que hice el curso para la obtención de la certificación VCP-410 y, hoy, al hilo de un artículo aparecido en el Blog de la Virtualización en Español, de nuestro gran maestro Jose María Gonzalez, retomo una de sus enseñanzas.
¿Cómo detectar problemas de latencia en disco de un ESXi? Dentro de nuestra herramienta de rendimiento, nos fijaremos en los siguientes contadores:
-
Kernel command latency.- tiempo medio empleado por el VMkernel para procesar un comando SCSI. Un número alto en este contador, (entre 2 a 3 milisegundos, puede significar:
- Que la cabina tenga un exceso de trabajo
- O que el servidor ESX/ESXi tenga un exceso de trabajo.
-
Physical device command latency.- Mide el tiempo medio que el dispositivo físico (disco) necesita para completar un comando SCSI. Un número alto en este contador (depende d la cabina, pero, en general, este valor está entre 15 y 20 milisegundos), puede significar dos cosas:
- O la cabina va muy lenta.
- O la cabina tiene un exceso de trabajo.
Vayamos a un ejemplo real. Configuro el primer contador (Kernel command latency) para mi cabina de discos y este es el resultado:

En este caso nos fijamos en el último dispositivo, que es el que no está dando unos valores anómalos. Como se puede apreciar, la SAN es una HITACHI.

Por otro lado, ahora nos fijamos en el segundo contador, (Physical device command latency). Este valor, en principio, nos tiene que venir dado por el fabricante de la cabina, en mi caso HITACHI, pero yo no lo he conseguido. Me voy a basar en los estándares.
En este caso tenemos que los siguientes discos:
-
t10.HITACHI_770501211902.- Este disco está por encima de los 20 milisegundos.

-
t10.HITACHI_770501211901.- Este disco ronda los 11 milisegundos en media con ligeros picos por encima de los 20 milisegundos.



¿Cómo seguir desde aquí? Bien, sabemos qué maquinas componen la citada LUN, en mi caso contiene las siguientes Máquinas Virtuales (VM):

Habría que ir moviendo una a una cada VM a otra LUN y verificar cuál es la que está provocando este fallo.
El próximo día Iperf en modo gráfico.
Un saludo,
Medición del rendimiento – Networking con Iperf.
Uno de los problemas más difíciles de detectar hoy en día en las «grandes empresas» es ver que el rendimiento de la red es el correcto. Digo grandes empresas ya que o tienen subcontratados los departamentos de comunicaciones, o siendo de la misma empresa, se llevan a matar. Este es mi caso pero con una salvedad, aquí se inventó la técnica de «balones fuera».
Al grano. Utilizaremos la herramienta Iperf, válida para sistemas operativos tales como Sun Solaris, Linux, Windows, etc. Estos son todos los parámetros:

Destacamos los siguientes parámetros:
- -D instalación como servicio.
- -R Desinstalación (remove) como servicio.
- -i intervalo de tiempo en segundos entre reportes.
- -l longitud del buffer a leer o escribir (por defecto 8 KB)
- -u recepción de datagramas UDP en vez de tramas TCP que es la opción por defecto.
- -P n donde n es el nº de conexiones simultáneas.
- -t tiempo en segundos de transmisión (10 segundos por defecto)
- -w tamaño de ventana TCP.
- -f[bkmBKM] formato del resultado: bits/s, kilobits/s, megabits/s, Bytes/s, KiloBytes/s, MegaBytes/s.
Pruebas realizadas:
i) Básica.- Definimos un equipo como servidor y otro como cliente y ejecutamos el aplicativo en ambos equipos.-
Ejecutamos en el equipo servidor Iperf -s

Ejecutamos en el equipo cliente Iperf –c <equipo servidor>

En este caso tenemos un ejemplo claro de una pobre comunicación en una red de 100MBits. 38,7 Mbits/sec.

En este otro caso tenemos una mejor comunicación en una red de 100MBits. 75,1 Mbits/sec.
ii) Parametrizada.- Como hemos visto en la definición del comando vamos a utilizar los siguientes parámetros:
Servidor: Iperf –s –f MB –i1 (tamaño en MegaBytes e intervalos de 1 segundo)
Cliente: Iperf –c 10.144.8.123 –f MB –t 30 (tamaño en MegaBytes y durante 30 segundos de duración)

Bibliografía.
El próximo Iperf gráfico, Iometer, etc.
Un saludo,
